��Ʒ�߹ɷ�(688227.SH)����Ϣ��Ʒ�߹ɷ�����ս�Լ�����Ԥ�棬2025��12��25�� ���� �ڹ�����AI������ʩ������ص���ҵ�˳��У�Ʒ��������ƷԭAIһ���AI StationҺ��AI����վϵ�У��ԡ�������оΪ�ˡ���Ӳ����̬Ϊ�������ڼ�������Ϊ���������������漶AI�����ն˵�δ����Ⱥѵ����ȫջ�����������������
����01 �����ڷ��� AI StationҺ�乤��վ��������о�����漶�������
������ΪƷԭAI��Ӳ��ϵ�еĺ����ն˲�Ʒ��AI StationҺ��AI����վ�Ծ�����Ƭ�����Ľ�ԭD20 AI���ٿ�Ϊ��������������ͬ���Ƴ�����(AI Station D20-S)��˫��(AI Station D20-D)���Ŀ�(AI Station D20-Q)ȫ������ͣ��γɸ��Dz�ͬ��������IJ�Ʒ�ݶӡ�
����
���У���ԭD20 AI���ٿ��ǹ�����ʵ����ơ����졢��װ��������Ƭ�������ƶ�AI����������Ӧ�������ɿأ�����256GB�Դ棬INT8������ֵ��320TOPS��֧��FP32/FP16/BF16/INT8�ྫ�Ȼ�ϼ��㣬Ϊ��ģ�������ṩ��ʵӲ��֧�š�
�����������ܲ���ʵ�ֹؼ�ͻ�ƣ��������Ϳ��ȶ���������32B��������ģ�ͣ��Ŀ�����ƾ���оƬЭͬ�ܹ���Ʒ������4D���е��Ȳ��ԣ��ɵ�������Qwen 235B��DeepSeek 685B��ǧ�ڼ���ģ�����У��������漶����վ����ģ�Ͳ�����������ơ�
�������һ��ʽҺ��ɢ�ȼܹ���AI Stationϵ��ʵ�֡�������+������+���ȶ������������ƣ��ȴ���Ч�ʽϴ�ͳ��������40%���ɱ���߸����µ�������Ƶ������7��24Сʱ�������У�������������28dB(�ӽ�ͼ��ݻ�����)������칫��ʵ���ҵȰ���������
����ͨ��Һ��ϵͳ��С�ͻ����ɣ��Ŀ������Կɱ��ֽ��ջ�����ƣ���������ܶ���ռ������ԡ��������䷽�棬ȫϵ�л������֧��RAG(������ǿ����)���������Զ����������岿���ǰ��AIӦ�ó��������б�����������ģʽ��������˽��ȫ���ϣ���Ч��ܺ���������й���գ���������ͻ����ݺϹ�����Ϊ��ҵ�ṩ�����伴�á��Ĺ�����AI�����ն˽��������
����02 ϵ�в��֣�������о��������Ӳ����̬����
�������η������ǵ�һ��Ʒ��أ�����Ʒ�ߡ�������о��Ӳ��ϵ�л���ս�Եļ�����أ�������Ӳ��ȫ����+����ȫջ��+��̬���Ż�������������AI������̬��ϵ��Ϊ��ͬ�㼶��AIӦ�������ṩȫ��·֧�ţ�
����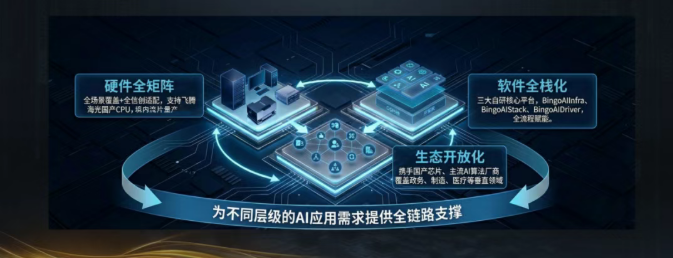
l?Ӳ����Ʒ����ȫ��������+ȫ�Ŵ�����
�����������DZ߶�-���漶-��������Ⱥ������ƷԭAIһ�����Ʒ�ߣ����з�����������1����8����16���ȶ������(��PYD10-MIN/PRO/MAX���ͺ�)�����漶��Ϊ���η�����AI Station����վϵ�У��ṩ1��(D20-S)��2��(D20-D)��4��(D20-Q)ȫ����ѡ��
����ȫϵ��Ӳ��ȫ��֧��ȫ�Ŵ��ܹ������������ڡ��������������CPU��������䣬�����㲿���������ܹ������ɿأ����̶ȱ��Ϲ�Ӧ����ȫ�ɿأ�������ӱ�Ե�������ƶ˴��ģ�������ȵ�ȫ��������
����l?����ȫջƽ̨��ȫ���̸���AI������ά
���������������к�������ƽ̨�γ�Эͬ����������BingoAIInfra�������ƽ̨��BingoAIStackѵ��һ�廯ƽ̨��BingoAIDriver����Ӧ��ƽ̨������BingoAIInfra�߱�������GPU�и�����ԭ��������������ʵ�ֹ���������Դ�ľ�ϸ���������Ч���ã�BingoAlStack�ṩһվʽMaaS���������ż���չģ��ѵ�������𡢲����뿪����֧�ֶ��û���������Эͬ���£�BingoAIDriver��۽���ҵӦ����أ��ṩ��������Ӧ������뼯���������������AIӦ�ÿ����ż���
����l?������̬������Я�ֻ�鹲����ҵ��̬
�������ֿ��Ź�Ӯ���Ʒ���������뽭ԭ�Ƽ��ȹ���оƬ���̴�����ս��Э����ͬʱ������������AI�㷨���̡���ҵISV��ȫ�����䣬�����ǻ������������졢ҽ�ƽ������ǻ۽�ͨ�ȶ����ֱ����ͨ���������������������������ģʽ���ƶ�����AI������̬�Ĺ�ģ����������������
����l?��ҵ�Ͽ��뽱���������ʵ����֤
����ƷԭAIһ���ϵ��ƾ��ȫջ������������Խ���ܣ���ն�������ҵȨ���Ͽɣ������ڵ�27���й������������������ٻ�2025����˹����ܴ��²�Ʒ�������Ӧ����Ŀ�������ǻ۽�ͨ��������Ƶ��ͼ������ʶ��ϵͳ���ڵ�һ���ۺϽ�ͨ�����ģ�������崴��Ӧ�ô���ȫ���ܾ�����ն��һ�Ƚ���Ʒ�߹ɷ�Ҳƾ���ϵ�в�Ʒ����ҵ��سɹ�����ѡ��2025�й�AI��ҵ��ػ�����ʩ������Top20����
����03 2026չ������ԭT800��ģ��ѵ��һ��AIоƬ��ê�����ģ��������
����2026�꽭ԭ�Ƽ����Ƴ�T800��ģ��ѵ��һ��AIоƬ���Ա�Ӣΰ��H800оƬ���۽����ģAIģ��ѵ�������������Ծ�����Ƭ����ʵ�ָ����Լ۱�ѡ��оƬ�����������������ù����Ƚ��������Ƚ���װ�������죬ͨ�����ڹ������յ����PPA(���ġ����ܡ����)�Ż����ڱ��������ɿص�ͬʱʵ��Ч��Ծ����ԭ��֧��FP8/FP4�߾��ȼ�����٣�����ڴ�ͳFP16���ȿɼ���50%�ڴ�ռ�ã���������ڴ����ѹ�����ڱ����㷨���ȵ�ǰ��������ѵ��Ч�ʣ�����144GB������HBM3E�洢��ƾ��ߴ���������������Ч����AIѵ�����ڴ�ƿ�����䱸SmartLink������ٻ���������֧�����256�����ڵ㼯Ⱥ���𣬿�ʵ�ֳ����ģ����ѵ�������ĸ�ЧЭͬ���ȡ�
����
? ����
�뺣�������߶�GPU��Ʒ�Աȣ���ԭT800����������Ϊͻ���������H20 GPU��ʵ������FP8/FP16��������������Ч�ܷ�����ȫ��֧��FP4���ȣ�����ı���������ͻ�ƣ��洢������H20�����������ɳ��س������ģ�ͣ�����Դ������������������������Ч�����ƿ���������H800 GPU����������ʵ�ַ�����֧�ָ����ģ���ڵ㼯Ⱥ������洢�������Դ����Ҳ�������ԣ���һ�����ϸ����������µ��ȶ��������ԭT800���ܶԱ���ʸ߶�����оƬ��Ϊ��ҵ����ģ�����С���ҵAI���������ṩ�����ĵ���������֧�š���ԭT800���ܶԱ���ʸ߶�����оƬ��Ϊ��ҵ����ģ�����С���ҵAI���������ṩ�����ĵ���������֧�š�
������˾��ʾ����ԭT800������ͻ�ƣ�����ӡ֤�˹���AIоƬ�ļ������ף����뱾�η�����AI Station�γ�ս�Ժ�Ӧ����ǰ��ê��δ�����ģ���������߹�ͬ����Ʒ�ߡ������ɿء�ȫջ���ǡ����ڵ�����������ս�ԡ�
����?








CopyRight@2010-2026 ��� All Right Reserved
�н��Ѷ����עȫ��ƾ���̬�����г�����������